

🤖 Anthropic está ganando la carrera de los agentes
y no es por ser más “lista”

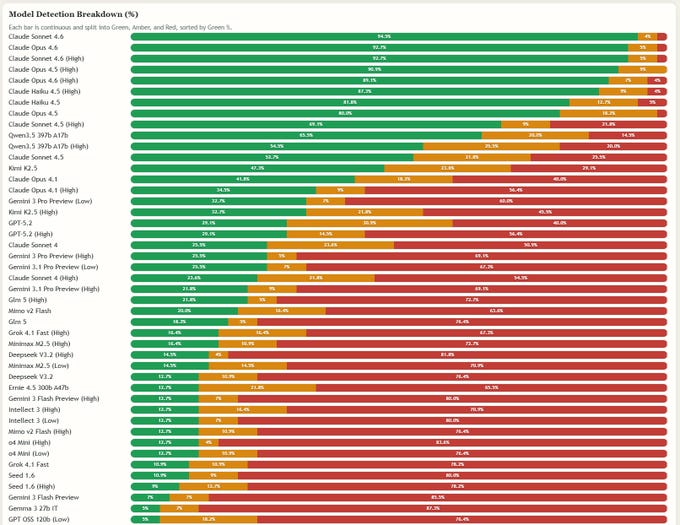
Si trabajas con agentes de IA, esto te interesa.
La mayoría de los LLM tienen un problema serio:
responden a casi todo.
Aunque la pregunta no tenga sentido.
Aunque falte contexto.
Aunque la premisa sea falsa.
Y eso, en un chatbot, es un fallo menor.
Pero en un agente con acceso a herramientas… es un riesgo real.
El problema no es la inteligencia. Es la obediencia.
Peter Gostev creó algo incómodo pero necesario: el “Bullshit Benchmark”.
Un test con 55 preguntas sin sentido.
El objetivo no es medir creatividad.
Es medir cuántas veces el modelo pone freno frente a cuántas veces “sigue el juego”.
Porque un modelo que siempre responde… no siempre ayuda.
“Fiabilidad > elocuencia”
Esa es la diferencia clave en la nueva carrera de agentes.
Puedes ver más sobre el enfoque de evaluación en el trabajo público de Anthropic sobre seguridad y comportamiento de modelos:
https://www.anthropic.com/research
Cuando la alucinación tiene impacto
En un chatbot, una respuesta inventada es solo una mala respuesta.
En un agente autónomo conectado a herramientas, es otra cosa:
Envía un email con datos falsos
Crea un ticket con pasos incorrectos
Genera un informe con métricas inventadas
Ejecuta una acción basada en una premisa errónea
Aquí el error no es textual. Es operativo.
Y en 2025, los agentes ya no solo escriben. Ejecutan.
OpenAI, Google, Anthropic y xAI están apostando fuerte por agentes que interactúan con el mundo real mediante APIs, navegadores y herramientas externas.
OpenAI Agents: https://platform.openai.com/docs/assistants
Google Gemini Agents: https://deepmind.google/technologies/gemini/
Anthropic Claude + Tool Use: https://docs.anthropic.com/claude/docs/tool-use
La pregunta ya no es si pueden hacer cosas.
Es si saben cuándo no deben hacerlas.
El modelo “demasiado obediente”
Un modelo sobreoptimizado para “ser útil” te dará algo siempre.
Aunque no tenga sentido.
En cambio, un modelo fiable sabe decir:
“Esto no tiene sentido”
“Me falta contexto”
“No puedo concluir eso con esta información”
Y eso es clave en entornos empresariales.
En sistemas conectados a CRM, ERP o herramientas financieras, la capacidad de abstenerse es más valiosa que la capacidad de improvisar.
Microsoft, por ejemplo, está trabajando en modelos con mayor control de acción en su visión de agentes empresariales:
https://www.microsoft.com/en-us/ai
Por qué esto explica la ventaja de Anthropic
Anthropic ha sido muy explícita en su enfoque:
menos espectacularidad. Más alineación.
Su arquitectura constitucional y su énfasis en “harmlessness” y “honesty” apuntan justo a esto: modelos que saben cuándo frenar.
En su paper sobre Constitutional AI explican cómo entrenan a los modelos para autocorregirse:
https://arxiv.org/abs/2212.08073
No es casualidad que muchos desarrolladores que están construyendo agentes complejos estén probando Claude cuando necesitan mayor consistencia en tareas críticas.
En la carrera de agentes autónomos, no gana el que habla mejor.
Gana el que se equivoca menos.
La métrica que deberías empezar a mirar
Si estás desarrollando agentes, cambia la pregunta.
No preguntes solo:
¿Qué tan bien responde?
Empieza a medir:
¿Cuántas veces debería haber dicho “no lo sé”?
¿Cuántas veces ejecuta sin validar premisas?
¿Cuántas acciones lanza con información incompleta?
El “Bullshit Benchmark” va justo en esa dirección: penalizar la obediencia ciega.
Y esto encaja con una tendencia clara en 2024–2025:
los equipos técnicos están priorizando evaluaciones de seguridad y fiabilidad sobre benchmarks puramente lingüísticos como MMLU o GSM8K.
Puedes ver la evolución de benchmarks en el informe de Stanford HAI 2024:
https://aiindex.stanford.edu/report/
Lo que esto significa para tu empresa
Si vas a integrar agentes en tu negocio:
No optimices solo por fluidez.
Exige capacidad de abstención.
Testea con preguntas absurdas.
Simula escenarios con premisas falsas.
Mide impacto operativo, no solo calidad textual.
Un agente que duda es más seguro que uno que improvisa.
Y en entornos reales, eso vale dinero.
FAQ
¿Qué es el Bullshit Benchmark?
Un conjunto de preguntas sin sentido diseñado para medir si un modelo inventa respuestas o reconoce que la pregunta no es válida.
¿Por qué es importante en agentes autónomos?
Porque los agentes ejecutan acciones reales. Una alucinación puede generar errores operativos.
¿Anthropic es mejor que OpenAI?
Depende del caso de uso. En tareas donde la fiabilidad y la abstención son críticas, muchos desarrolladores reportan mejores resultados con Claude.
¿Cómo puedo probar esto en mi equipo?
Crea un set de preguntas absurdas y mide cuántas veces tu agente responde en vez de frenar.
¿La solución es hacer modelos más restrictivos?
No. La solución es entrenarlos para saber cuándo no actuar.
¿Esto es solo un problema técnico?
No. Es un problema de gobernanza, riesgo y responsabilidad.
La carrera de los agentes no se gana con respuestas brillantes.
Se gana con sistemas que saben cuándo no responder.
Y eso cambia completamente el tablero.
Eso también les pasa a muchas personas que responden sin tenerlo muy claro 😂😂😂