

🤖🪪 La UE quiere que el contenido generado con IA se identifique siempre y las empresas no pueden mirar a otro lado
La Comisión Europea ya ha puesto el borrador sobre la mesa: el First Draft Code of Practice on Transparency of AI-Generated Content.

No es todavía ley dura, pero es la hoja de ruta oficial para aplicar el artículo 50 del AI Act. Y conviene tomárselo como lo que es: el ensayo general antes de que empiecen las multas.
Este código no habla de ciencia ficción ni de futuros lejanos. Habla de algo muy concreto: cómo marcar, detectar y etiquetar contenido generado o manipulado con IA, y quién es responsable en cada punto de la cadena.
Si tu empresa usa IA para generar texto, imágenes, vídeo o audio, esto va contigo. Si además publicas contenido informativo, marketing, formación o comunicación corporativa, todavía más.
Fuente: First Draft Code of Practice on Transparency of AI-Generated Content
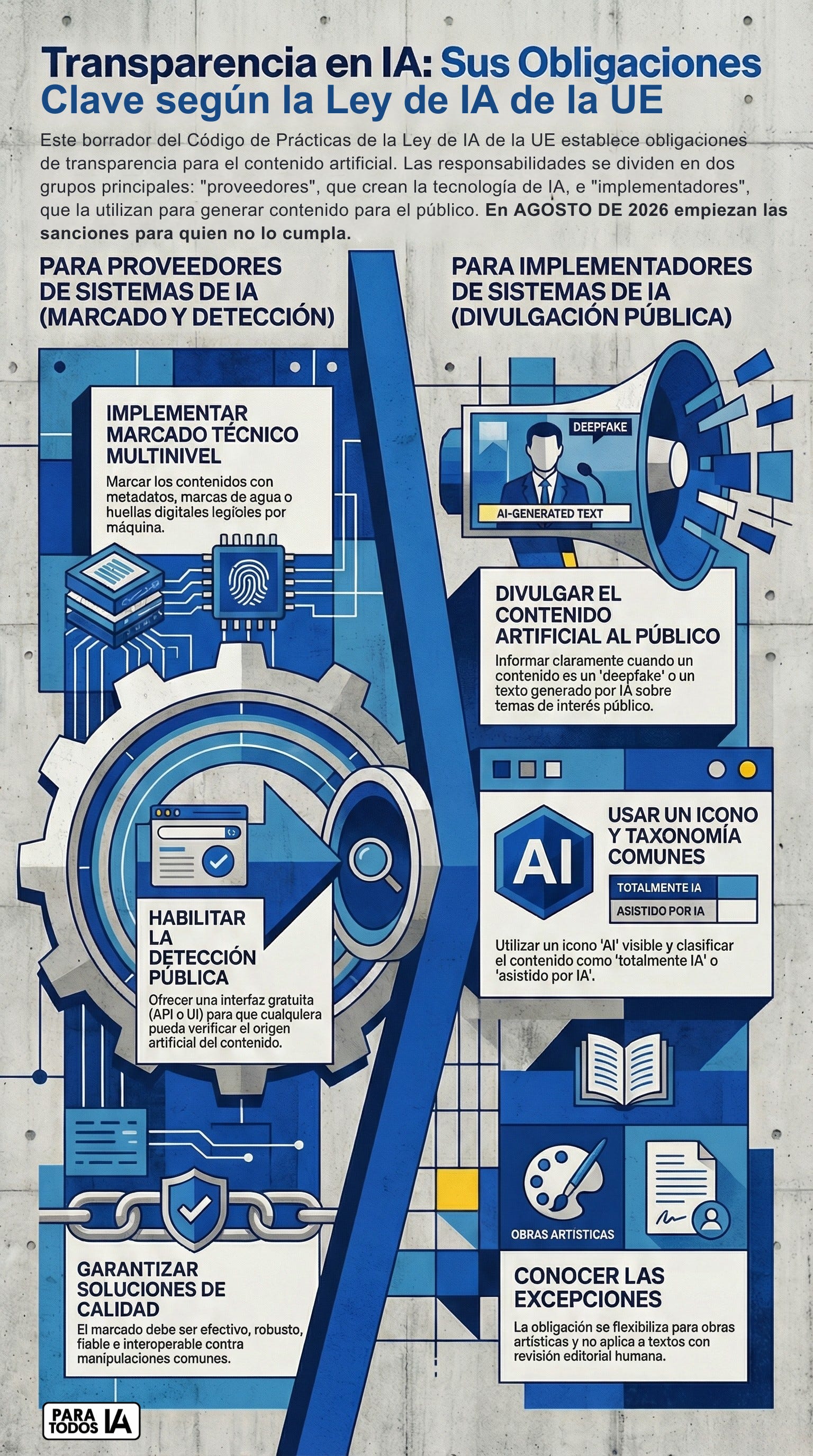
🧩 Dos mundos distintos: proveedores y empresas usuarias
El documento divide claramente el juego en dos roles, y no es un matiz legal sin importancia.
Por un lado están los proveedores de sistemas de IA generativa. Es decir, quienes crean los modelos o las herramientas. Aquí entran desde grandes plataformas hasta startups que ofrecen generación de contenido como servicio.
Por otro lado están los deployers, que en la práctica son las empresas y profesionales que usan esas herramientas para publicar contenido.
La UE deja claro que no basta con decir “yo uso una IA de terceros”. Cada rol tiene obligaciones distintas y acumulativas.
🔐 Para proveedores: marcar el contenido desde dentro
Si desarrollas o vendes tecnología de IA generativa, el mensaje es directo:
el contenido tiene que salir ya marcado de origen.
El código propone un enfoque de varias capas:
– Metadatos con información de procedencia
– Marcas invisibles tipo watermark
– Fingerprinting o registros para poder verificar el origen después
– Detectores accesibles para terceros
Nada de una solución mágica única. La Comisión asume que no existe y exige combinarlas. Además, los sistemas de detección deben seguir funcionando incluso si la empresa desaparece. Sí, han pensado en eso. Por ahora el único sistema que podría funcionar es el de SynthID de Google.
Y si trabajas con modelos open-weight, también hay deberes: marcas estructurales en los pesos para que terceros puedan cumplir la norma.
🏢 Para empresas y profesionales: etiquetar bien o asumir el riesgo
Aquí viene la parte incómoda para marketing, comunicación, medios, formación y consultoría.
Si publicas:
– deepfakes (imagen, vídeo o audio que simula personas o hechos), o
– texto generado por IA para informar sobre temas de interés público
tienes que avisar de forma clara y visible.
El código propone un sistema común basado en:
– una taxonomía clara: contenido totalmente generado vs. contenido asistido
– un icono visible (por ahora provisional, luego común a toda la UE)
– reglas específicas según formato: vídeo, imagen, audio, texto
Y ojo al detalle importante: si hay revisión humana real y responsabilidad editorial, el texto puede quedar exento del etiquetado. Pero eso hay que poder demostrarlo con procesos internos y documentación. No con “lo revisamos un poco”.
🎨 ¿Y el contenido creativo, satírico o artístico?
Aquí la UE sorprende para bien. No exige cargarse la experiencia creativa.
En obras artísticas, satíricas o de ficción, el aviso debe existir, pero de forma proporcionada y no intrusiva. Un icono discreto, un aviso contextual, algo que informe sin estropear la obra.
Eso sí, cuando entran personas reales, política o temas sensibles, las salvaguardas se refuerzan.
🧠 Accesibilidad y alfabetización, no solo cumplimiento
Otro punto interesante: el código insiste mucho en accesibilidad.
Los avisos deben ser comprensibles también para personas con discapacidad:
– lectores de pantalla
– audio para contenido visual
– contraste y tamaño adecuados
Y además se pide a las empresas que formen a sus equipos. No solo a legal o compliance, también a quienes crean y publican contenido.
Esto no va de poner un icono y olvidarse. Va de cambiar procesos.
📌 Qué deberían hacer ya las empresas
Aunque sea un borrador, hay tareas que no tiene sentido posponer:
– Mapear qué contenido se genera o se apoya en IA
– Diferenciar contenido interno, creativo y de interés público
– Definir cuándo hay revisión humana real y documentarla
– Preparar guías internas de etiquetado
– Exigir a proveedores información sobre marcas y detección
- Formación a todos los equipos
Esperar a que “salga la versión final” es la estrategia favorita para meterse en problemas más caros después.
⚠️ Por qué esto importa de verdad
Porque el AI Act no va de bloquear la IA. Va de responsabilidad y trazabilidad.
Y porque la confianza en el contenido digital está bajo mínimos.
La UE está dejando claro que, en adelante, no saber si algo lo ha hecho una IA no es aceptable. Ni para ciudadanos, ni para empresas, ni para marcas.
Y sí, es burocrático. Y sí, implica trabajo extra. Pero también pone reglas claras en un terreno que hasta ahora era puro salvaje oeste.
❓ FAQ rápida para empresas
¿Esto ya es obligatorio?
No todavía. Es un borrador de código de buenas prácticas, pero está diseñado para facilitar el cumplimiento del AI Act, que sí es obligatorio y tiene fecha para empezar a imponer sanciones: AGOSTO DE 2026.
¿Afecta a marketing y branded content?
Depende. Si es creativo o promocional, menos riesgo. Si informa sobre temas de interés público, más atención.
¿Basta con un aviso en letra pequeña?
No. La norma insiste en que debe ser claro, visible y comprensible en el primer contacto.
¿Qué pasa si uso varias herramientas de IA?
La responsabilidad sigue siendo tuya como empresa que publica el contenido.
¿Habrá un icono único europeo?
Sí, está previsto. De momento se permiten iconos provisionales tipo “AI / IA”.
¿Esto elimina la ventaja competitiva de usar IA?
No. Elimina la opacidad. No es lo mismo.